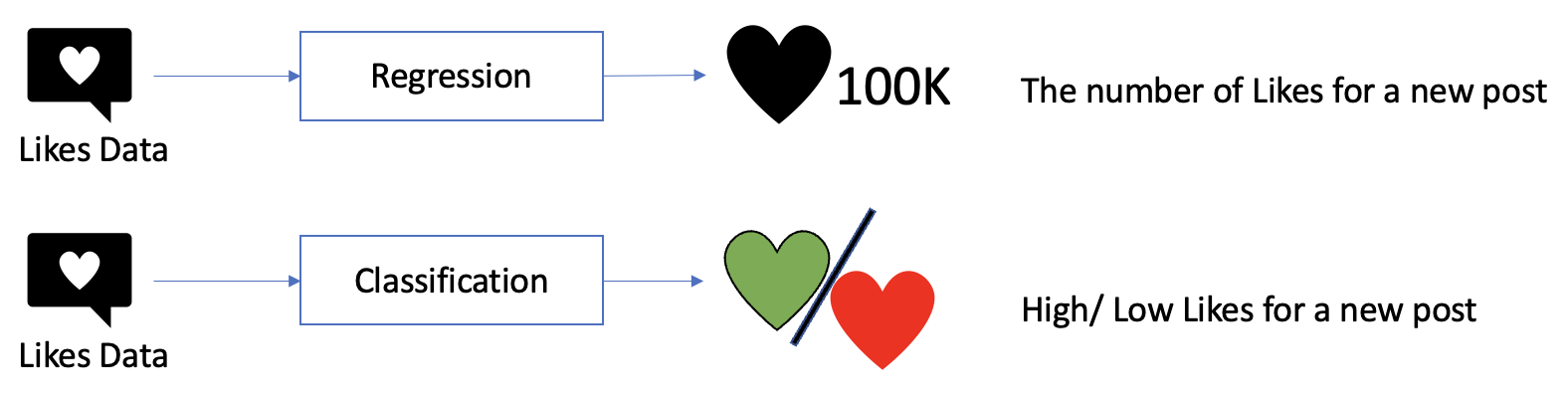
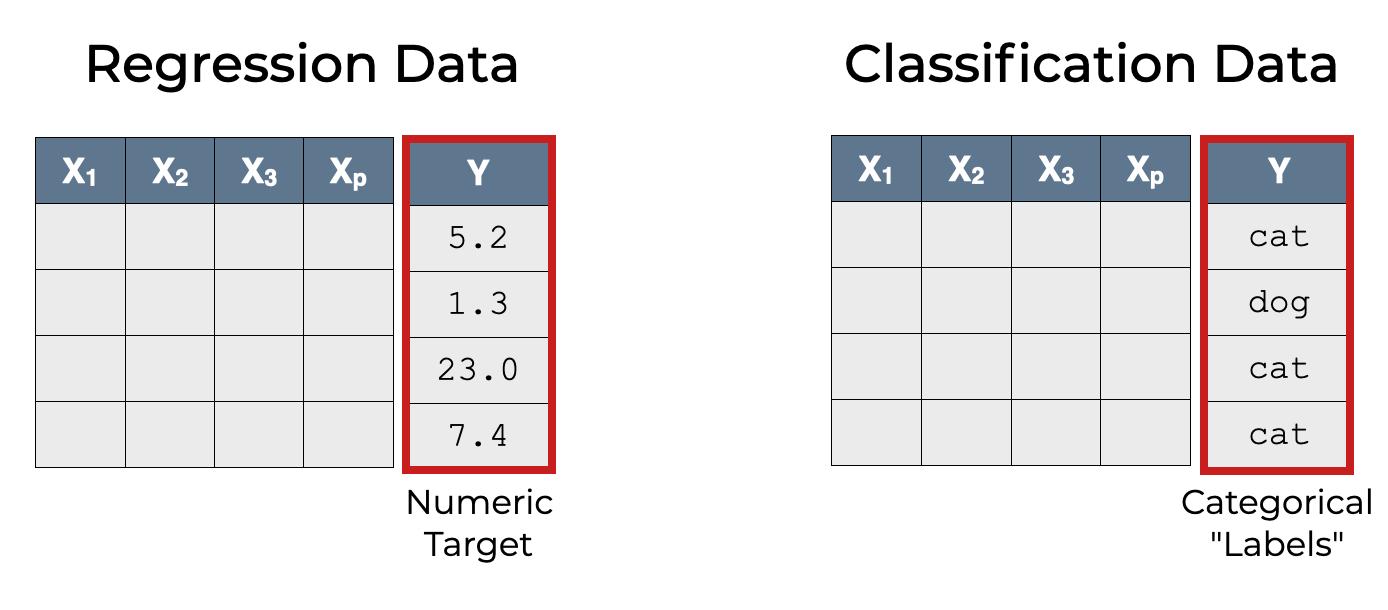
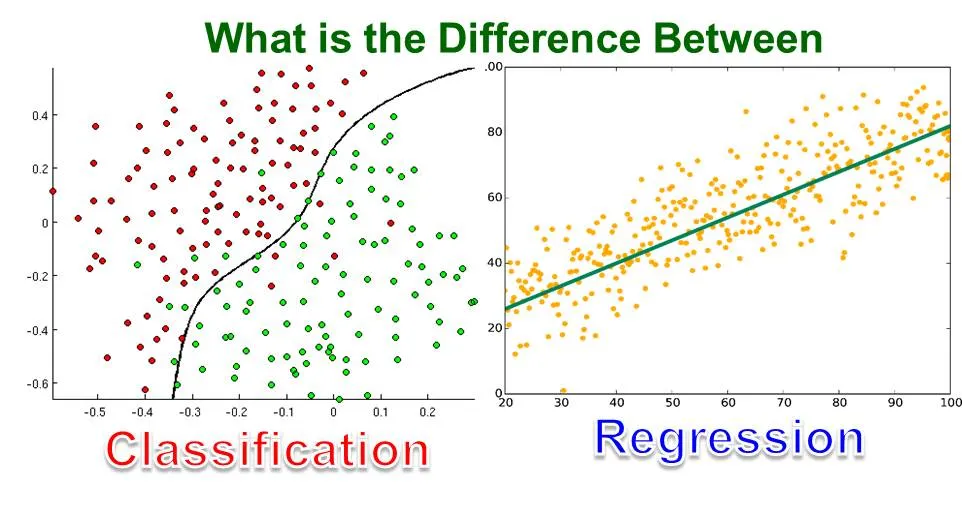
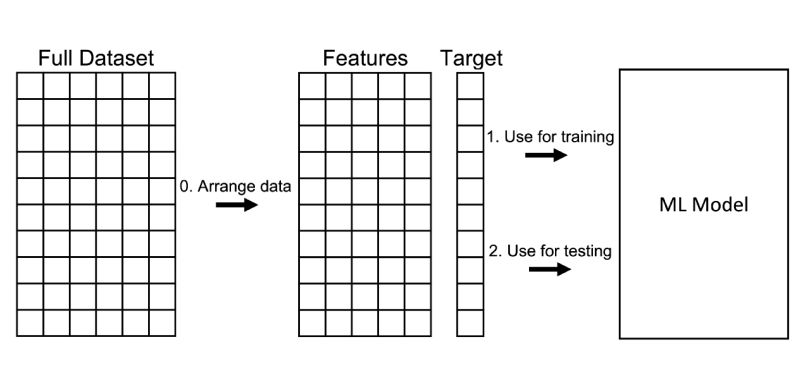
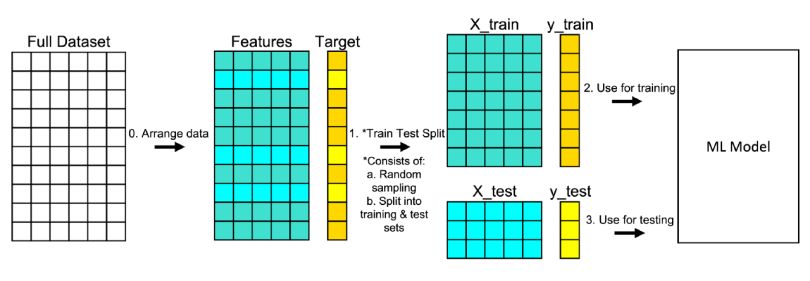
Bir Sınıflandırma modeli oluşturulduktan sonra bu model ile yapılan tahminlerin ne kadar doğru olduğuna dair değerlendirme yapılması gereklidir.
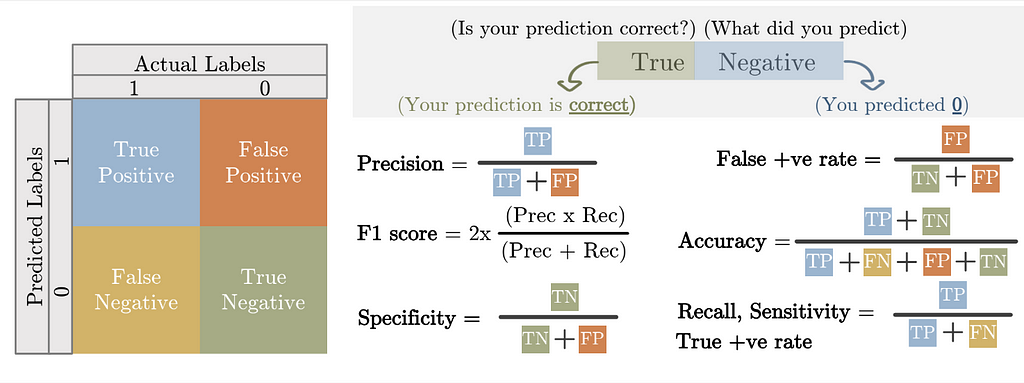
Aşağıda verilen confusion matrix (karşılaştırma matrisi) bir sınıflandırma modeline dair gerçekleşen durumları ve bu durumlara dair tahminleri verilmiştir.
True ve false değeri bu modele dair gerçek sonuçları, positive ve negative ise modele dair tahminleri göstermektedir.
Classification Performance Metrics
Tümör ve Hasta örnekleri ele alırsak, Normal örnekler negatif olarak, Tümör örnekleri de pozitif olarak değerlendirilebilir.
TP : Gerçekte Tümör olan hastayı (true/pozitif) Tümör olarak tahmin etmek (pozitif).
FP : Gerçekte Normal olan örneği (false/negatif) Tümör olarak tahmin etmek (pozitif). — > Type 1 Error
FN : Gerçekte Tümor olan örneği (true/pozitif) Normal olarak tahmin etmek (negatif). — > Type 2 Error
TN : Gerçekte Normal olan örneği (false/negatif) Normal olarak tahmin etmek (negatif).
Metrics
Accuracy(Doğruluk) : Doğru tahminlerin toplam veri kümesine oranıdır.
Precision(Kesinlik): Pozitif olarak tahmin edilen verilerin kaçının gerçekten pozitif olduğunu gösterir.
Recall or Sensitivity(Duyarlılık): Geliştirilen modelin pozitif olanların kaçını yakaladığını gösterir.
F1 Score(F1 Skoru): F1 score, precision ve recall değerlerinin harmonik ortalamasıdır. Sınıf dağılımı benzer olduğunda accuracy kullanılabilirken, dengesiz veri setleri söz konusu olduğunda F1 skor daha iyi bir metriktir.
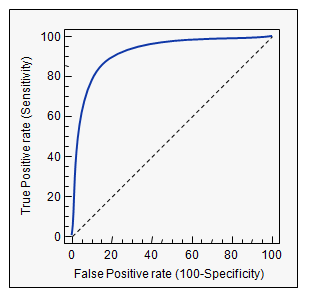
ROC Curve(ROC Eğrisi): Yanlış pozitif oranı ve gerçek pozitif oranı göz önünde bulundurarak x ekseninde ve y ekseninde 0’dan 100’e kadar olan değerlerin üzerinde bir eğri oluşturulur. Bu eğrinin altında kalan alana Area Under Curve (AUC) adı verilir. Bu alanın büyük olması modelin başarılı olduğunu gösterir. Grafikte yer alan mavi çizgi; ne kadar geniş bir alan kaplıyorsa modelin tahmin başarısı o kadar yüksek, ortadaki kesikli çizgiye ne kadar yakınsa modelin başarı oranı o kadar düşüktür.
ROC Curve
Why too many metrics?
Neden birden fazla metrik kullanılıyor, bir örnek ile görelim. Yandaki durum için, 8 Normal ve 2 Tümör olan bir durumda, her örnek için Normal diye tahminde bulunursak. True Negatif (TN) sayısı 8 ve False Negatif (FN) sayısı ise 2 olmaktadır.
Bu durumda, doğruluk, accuracy
ACC = (TP + TN) / (TP + FP + TN + FN)
formülünden dolayı 8 / 10 = 0.8 yani %80 olarak hesaplanmaktadır.
Fakat, Duyarlılık/Sensitivity
SENS = TP / (TP + FN)
formülünden 0 çıkmaktadır.
Actual Label
Prediction
Tumor
Normal
Tumor
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Normal
Example
100 kişilik bir çalışmada, 25 Tümör hastası ve 75 Normal birey bulunmaktadır. Normal (negatif) olan 70 kişi Normal olarak tahmin edilmştir (TN: True Negatif). 5 kişi Normal olduğu halde Tümör olarak tahmin edilmiştir (FP: False pozitif). Gerçekte Tümör olan 15 kişi Tümör olarak tahmin edilmiştir (TP: True pozitif). Son olarak, 10 kişi Tümör olduğu halde Normal olarak tahmin edilmiştir (FN: False negatif). Bu duruma göre Confusion Matrix aşağıdaki gibi hesaplanacaktır.