Regresyon
MBG1032 - Doç.Dr.Alper YILMAZ
Özet
- Regresyon nedir? Korelasyondan farkı
- Basit doğrusal regresyon
- En küçük kareler yöntemi (OLS)
- Regresyon katsayılarının yorumlanması
- R² — Belirtme katsayısı
- Regresyon varsayımları (LINE)
- Artıkların incelenmesi
- Tahmin (prediction)
- Çoklu regresyon
- Biyolojik örnekler ve R uygulamaları
Korelasyon vs Regresyon

Regresyon nedir?
Regresyon, bir bağımlı değişken (Y) ile bir veya daha fazla bağımsız değişken (X) arasındaki ilişkiyi matematiksel bir modelle ifade eden istatistiksel bir yöntemdir.
- Korelasyon: “Boy ve kilo arasında ilişki var mı?” → r = 0.95
- Regresyon: “Boyu 175 cm olan birinin kilosu kaç olur?” → ŷ = −105 + 1.1 × 175 = 87.5 kg
Regresyon yönlü bir analizdir: X’ten Y’yi tahmin ederiz. X ve Y’nin yerini değiştirirsek farklı bir denklem elde ederiz.
Basit doğrusal regresyon
Tek bir bağımsız değişken (X) ile bağımlı değişken (Y) arasındaki doğrusal ilişkiyi modellemek için kullanılır.
\[ Y = \beta_0 + \beta_1 X + \varepsilon \]
- \(\beta_0\) : kesim noktası (intercept) — X = 0 olduğunda Y’nin tahmini değeri
- \(\beta_1\) : eğim (slope) — X’teki 1 birimlik artışın Y’de oluşturduğu değişim
- \(\varepsilon\) : hata terimi (error) — modelin açıklayamadığı rastgele varyasyon
Tahmin denklemi (şapka = tahmin):
\[ \hat{Y} = \hat{\beta}_0 + \hat{\beta}_1 X \]
En küçük kareler yöntemi (OLS)
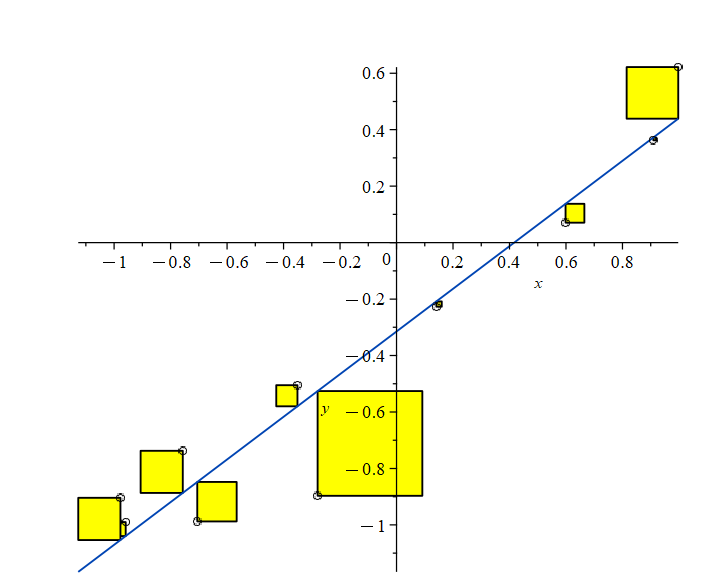
kaynak: OntarioTech
OLS formülleri
Eğim (\(\hat{\beta}_1\)) ve kesim noktası (\(\hat{\beta}_0\)) hesabı:
\[ \hat{\beta}_1 = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n (x_i - \bar{x})^2} \]
\[ \hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x} \]
Regresyon doğrusu her zaman \((\bar{x}, \bar{y})\) noktasından geçer.
Basit doğrusal regresyon — R uygulaması
Katsayıların yorumlanması
summary() çıktısını yorumlayalım:
- Intercept (β₀): Vücut ağırlığı 0 kg olsaydı kalp ağırlığının tahmini değeri. Biyolojik olarak anlamsızdır ama matematiksel olarak doğrunun Y eksenini kestiği noktadır.
- Bwt (β₁): Vücut ağırlığındaki 1 kg’lık artış, kalp ağırlığında ortalama β₁ gram artışa karşılık gelir.
- p-value: Eğimin sıfırdan farklı olup olmadığının testi. p < 0.05 ise X ile Y arasında istatistiksel olarak anlamlı bir doğrusal ilişki vardır.
- Std. Error: Katsayı tahmininin standart hatası. Küçük olması, tahminin kesin olduğunu gösterir.
Hesaplanan katsayılara göre, formül:
Hwt = 4.034 x Bwt - 0.356
Regresyon — görselleştirme
R² — Belirtme katsayısı
\(R^2\) (R-kare), bağımlı değişkendeki toplam varyansın yüzde kaçının model tarafından açıklandığını gösterir.
\[ R^2 = 1 - \frac{SS_{res}}{SS_{tot}} = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2} \]
- \(R^2 = 0\): Model hiçbir varyansı açıklamıyor (rastgele tahmin kadar kötü)
- \(R^2 = 1\): Model tüm varyansı açıklıyor (tüm noktalar doğru üzerinde)
- Basit regresyonda (tek bağımsız değişken) \(R^2 = r^2\) (Pearson korelasyonunun karesi)
Regresyon varsayımları
4 temel varsayım (LINE)
- Linearity (doğrusallık): X ile Y arasındaki ilişki doğrusal olmalıdır. Eğrisel bir ilişki varsa (parabolik, logaritmik gibi) doğrusal regresyon modeli bu ilişkiyi doğru temsil edemez. Kontrol: Artık vs tahmin grafiğinde rastgele dağılım olmalı, U veya S şekli olmamalı.
- Independence (bağımsızlık): Gözlemler birbirinden bağımsız olmalıdır. Bir gözlemin değeri diğerini etkilememeli. Örneğin aynı hastadan tekrarlı ölçümler alındıysa bu varsayım ihlal edilir.
- Normality (normallik): Artıklar (residuals) normal dağılmalıdır. Y’nin kendisinin değil, modelin hatalarının normal dağılması gerekir. Kontrol: Q-Q grafiğinde noktalar çapraz çizgi üzerinde olmalı.
- Equal variance (eşit varyans): Artıkların varyansı tüm X değerlerinde sabit olmalıdır. Yani model düşük X değerlerinde de yüksek X değerlerinde de aynı miktarda hata yapmalı. Kontrol: Artık vs tahmin grafiğinde huni şekli (yelpaze açılması) olmamalı.
Varsayımları kontrol etme — R ile
Diagnostik grafiklerin yorumlanması
R’ın plot(model) komutu 4 diagnostik grafik üretir, biz sadece ikisine bakıyoruz:
Residuals vs Fitted: Artıklar ile tahmin değerleri. Rastgele dağılım olmalı, bir desen (eğri, huni) varsa varsayım ihlali var demektir.
Normal Q-Q: Artıkların normalliği. Noktalar çapraz çizgi üzerinde olmalı. Uçlarda sapma varsa normallik ihlali var demektir.
Scale-Location varyans eşitliğini, Residuals vs Leverage grafiği de modele orantısız etkileyen noktaları gösterir.
“Kötü” örnekler
Residual-Fit veya QQ grafiği güzel olmayan iki örnek yapalım
treesadlı veride ağaçlara ait yükseklik, çap ve hacim hesaplamaları var. hacim ile çap arasında silindir hacmi ilişkisi olduğundan residual-fit eğrisinde bir örüntü ortaya çıkacaktır- kendimizin oluşturduğu enzim kinetiği verisinde doğrusal olmayan bir ilişki varken, doğrusal regresyon modelleme yaptığımızda residual-fit grafiğinde örüntü oluşacak ve QQ grafiğinde sapmalar olacaktır
trees veri seti
Kotü model 1
Kotü model 2
Michaelis-Menten benzeri doz-yanıt verisi
Regresyon ile tahmin
Çoklu doğrusal regresyon
Birden fazla bağımsız değişken ile Y’yi modelleme:
\[ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p + \varepsilon \]
Her \(\beta_j\): diğer değişkenler sabit tutulduğunda, \(X_j\)’deki 1 birimlik artışın Y’deki etkisi.
Düzeltilmiş R² (Adjusted R²): Çoklu regresyonda her yeni değişken R²’yi şişirir. Adjusted R² gereksiz değişkenleri cezalandırır:
\[ R^2_{adj} = 1 - \frac{(1-R^2)(n-1)}{n-p-1} \]
Çoklu regresyon — R uygulaması
Çoklu regresyon — model detayları
Yani;
\[\text{mpg} = -3.16 \times \text{wt} - 0.01 \times \text{hp} - 0.94 \times \text{cyl} + 38.75\]